Typical Scenarios
Prodia creates value across three high-value production scenarios and connects analytical work directly to production outcomes.
1. Three core scenario groups
| Core scenario group | What customers actually care about | Delivered value |
|---|---|---|
| Process optimization | How can a new specification be stabilized faster? How should parameters be set, curves adjusted, and recipes selected? | faster stabilization, less trial-and-error loss, clearer optimization path |
| Operational efficiency optimization | Why are output, unit consumption, and takt deteriorating? Which lever should be optimized first? | faster main-cause visibility, faster loss decomposition, faster prioritization |
| Equipment efficiency optimization | How should operating fluctuation be interpreted? What should be checked first after an alarm? When should equipment risk be addressed earlier? | earlier anomaly exposure, less downtime loss, more targeted maintenance action |
2. Scenario 1: Process optimization
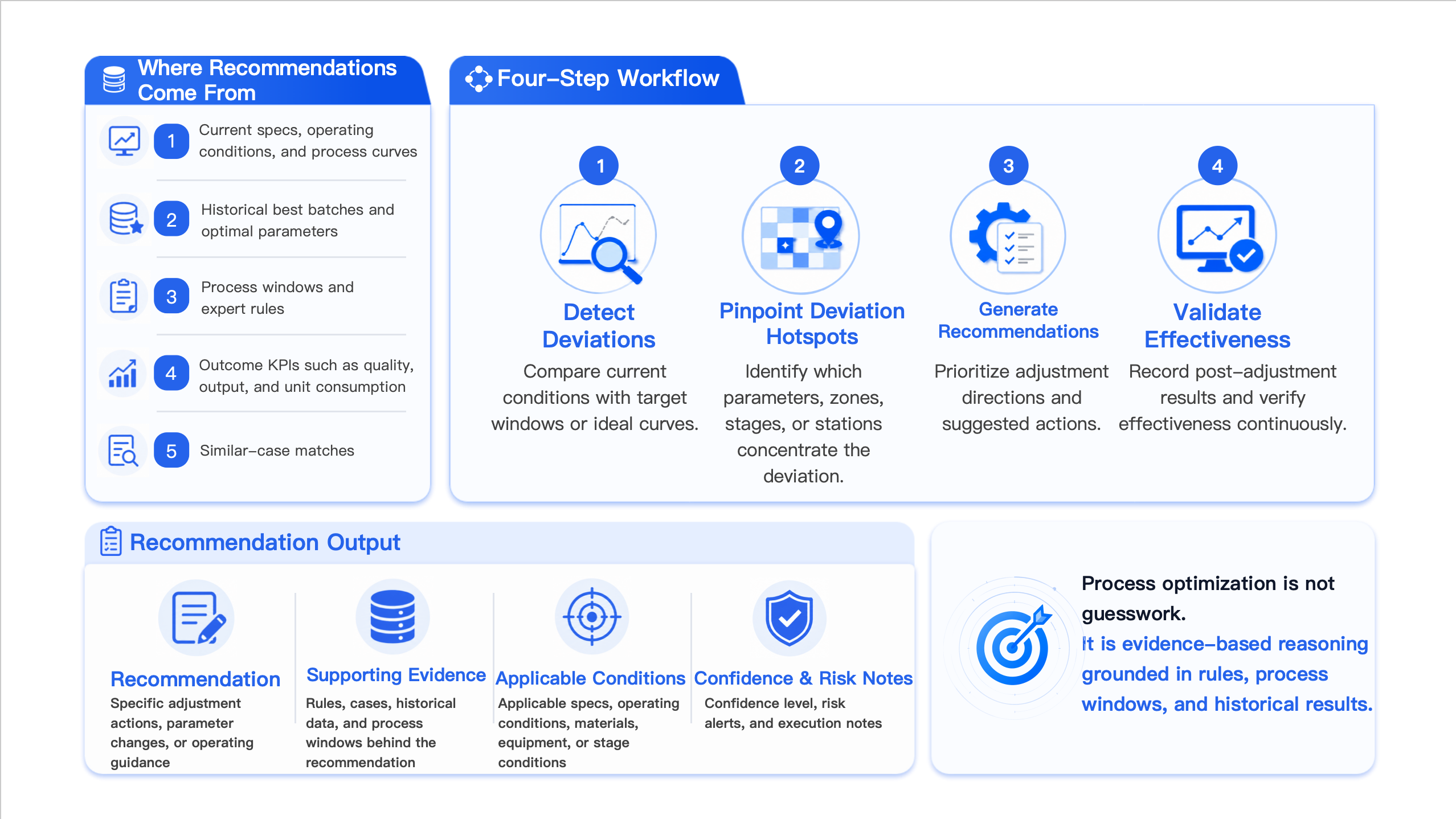
Process optimization is often the easiest entry point for customers to recognize value because it maps directly to practical questions such as how quickly a new specification can be stabilized, which parameter should be adjusted first, and how trial loss can be reduced.
- Audience: process engineers, quality engineers, production supervisors
- Typical questions: how to set parameters, tune curves, choose recipes, and move from trial tuning to stable production faster
- What Prodia provides:
- target process-window matching
- current deviation identification
- parameter adjustment suggestions
- recipe recommendations
- post-launch stabilization support
- Result value:
- shorter commissioning cycles
- clearer tuning paths
- faster arrival at stable production
- lower loss from process fluctuation
Process recommendations come from combined reasoning over the current specification, operating condition, process curves, successful historical batches, expert rules, and actual result performance.
3. Scenario 2: Operational efficiency optimization
Operational efficiency optimization is more closely aligned with the questions management teams and production leaders care about most: why results worsened and where action should start first.
- Audience: management, production supervisors, process teams
- Typical questions: why output was missed, which part increased unit consumption, where takt loss came from, and which lever should be optimized first
- What Prodia provides:
- business indicator overview
- fluctuation explanation
- loss-source decomposition
- priority optimization guidance
- Result value:
- faster cause visibility
- faster loss-structure understanding
- faster prioritization of the next move
4. Scenario 3: Equipment efficiency optimization
Equipment efficiency optimization focuses on whether anomalies can be detected earlier, whether downtime can be reduced, and whether maintenance action can become more targeted.
- Audience: equipment engineers, maintenance teams, production supervisors
- Typical questions: what to check first after alarms, which parameters should be reviewed together, which devices are already degrading, and which maintenance actions should move forward
- What Prodia provides:
- anomaly trend recognition
- alarm linkage analysis
- operating deviation judgment
- inspection and intervention guidance
- predictive maintenance support
- Result value:
- earlier exposure of critical anomalies
- less downtime loss
- more targeted maintenance action
- more stable equipment performance
5. Why these scenarios fit a first pilot
For a first pilot, the following three topics usually create the clearest visible value:
- stabilizing a new specification faster
- explaining why output / unit consumption / takt deteriorated
- identifying critical equipment anomalies earlier
These topics demonstrate three things clearly:
- the system forms operational judgment and supports follow-through
- the site can reuse expert methods and historical experience more consistently
- the analysis connects directly to stable production, efficiency, consumption, and loss outcomes